Часть 8. Akka Streams и реактивные потоки
Страничка курса: https://maxcom.github.io/scala-course-2018/
План
- Статус по практическому заданию
- Практическое задание: обновление ленты в акторе
- Зачем нужны асинхронные потоки?
- До streams: back pressure на акторах
- Akka Streams
- Reactive Streams - стандартное API
- Akka Streams в Play
План задания
- Классификатор текстов
- Reads для vk.com (только reads! writes не нужно)
- Стемминг и диагностика
- Сервис категоризации
- Оценка сообщений соц. сетей - API vk.com
-------- мы находимся здесь ------- - Опрос новых записей
хранение состояния на диске
Практическое задание: обновление ленты в акторе
- Загрузку ленты и классификацию выносим в актор
- Актор хранит ленту в памяти, запросы Get и Refresh
- Дубликаты выбрасываем по id
- Ленту автоматически обновляем раз в 3 минуты
Как использовать акторы в контроллерах Play?
@Singleton // обязательно! иначе акторы будут размножаться
class DemoController @Inject()(cc: ControllerComponents,
wsClient: WSClient, actorSystem: ActorSystem)
extends AbstractController(cc) {
private val helloActor = actorSystem.actorOf(...)
подробнее в документации
Akka Streams
Зачем нужны асинхронные потоки?
Например:
- Поточная отдача HTTP ответов
- Поточная обработка данных
Обработчик HTTP запроса - функция
def controller(request: Request): Response
def controller(request: Request): Future[Response]
хорошо для простых задач с маленькими ответами
Как отдать большую выборку, например из БД или другого сервиса?
В классических сервлетах писали так:
override def service(rq: ServletRequest,
rs: ServletResponse): Unit = {
val input: ResultSet = ??? // запрашиваем данные у сервиса
try {
while (input.next()) {
val line = input.getString(DataColumn) // ждем БД
rs.getOutputStream.println(line) // ждем клиента
}
} finally {
input.close()
}
}
(servlet 2.x)
Отдача поточная, но:
- занимаем поток под клиента
- лишаем контейнер возможности оптимизировать ввод-вывод
- чтение и обработка - только синхронные
- один источник данных
Можно ли улучшить время отклика отдавая данные по мере готовности?
Да, например классический веб:
- Стили и шрифты в "шапке"
- "Ощущения" прогресса загрузки
- Рендеринг в процессе загрузки
- Подгрузка картинок и ресурсов в процессе
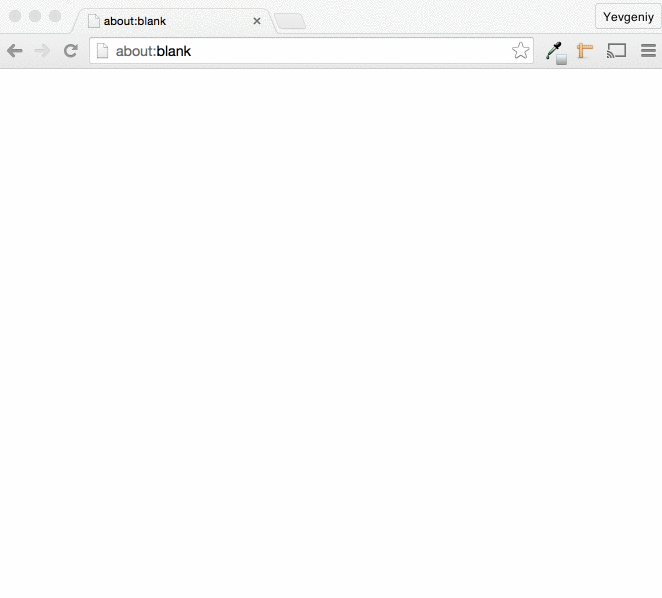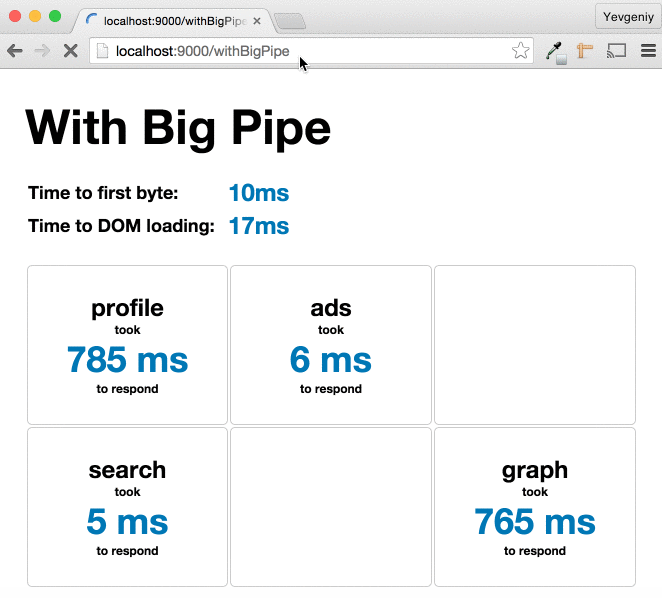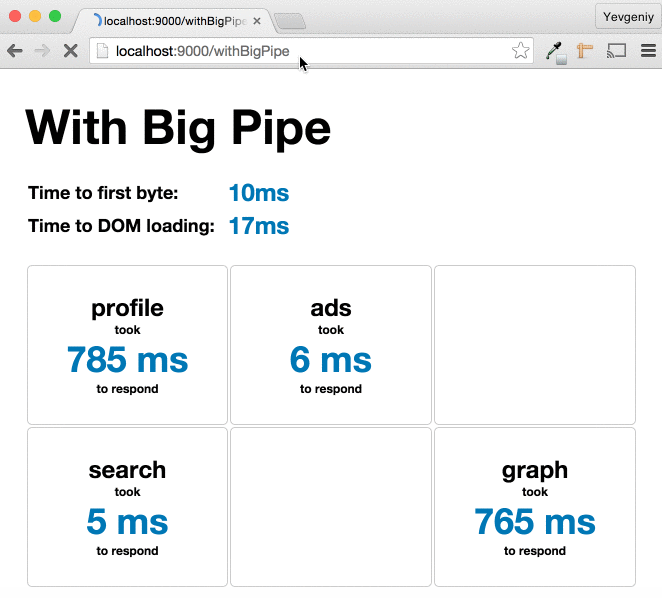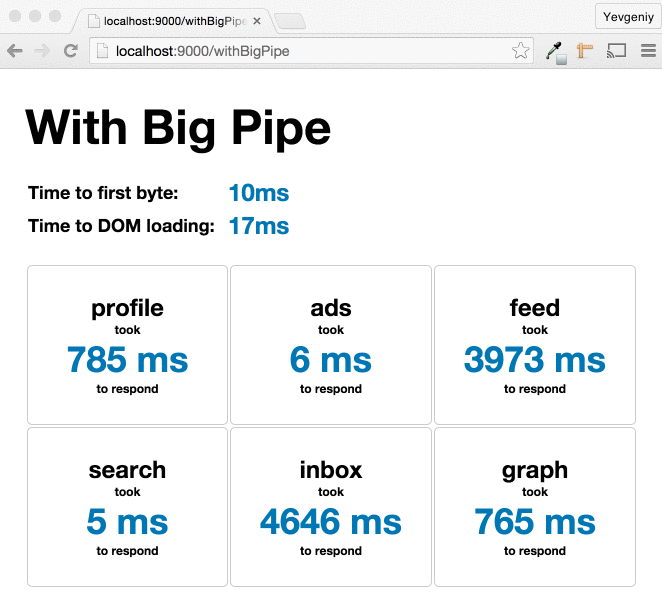
Более современный пример:
Ping-Play: Big Pipe Streaming for the Play Framework
by Yevgeniy (Jim) Brikman
картинка из статьи:
Еще применения:
- Отдача потоков событий
- Оптимизация в API между сервисами
Server Sent Events
Передача потока событий с сервера в браузер.
Стандарт из семейства HTML5
Клиент запрашивает URL,
в ответ - бесконечный поток событий
data: {"user":"Вася","message":"Вошел в систему"}
data: {"user":"Вася","message":"Написал комментарий"}
...
Поточная обработка данных
Сихронный режим не позволяет хорошо
- Смешивать разные источники
- Применять конвеер из асинхронных и параллельных обработчиков
- Управлять скорость; группировать по времени
- Передавать результат в несколько назначений
Можно ли собрать такой конвеер на акторах?
Можно, но нужен back pressure / flow control.
До streams: back pressure на акторах
Пример: один producer / один consumer
class Producer(consumer: ActorRef,
source: Iterator[Int]) extends Actor {
private var current: Int = 1
private var lastAck: Int = 0
sendNext()
private def sendNext(): Unit = ???
override def receive: Receive = {
case Ack(n) ⇒
lastAck = n
sendNext()
}
}
private def sendNext(): Unit = {
while (source.hasNext && current - lastAck < MaxProcessing) {
consumer ! Data(source.next(), current)
current+=1
}
if (!source.hasNext) {
consumer ! Finished
}
}
Минусы?
- В реальном коде flow control сложнее
- Смеживание "бизнес-логики" и flow-control
- Дублирование логики flow-control в разных реализациях
Akka Streams
Библиотека для работы с асинхронными потоками, построенная на акторах Akka.
Подключаем в build.sbt
// версии akka-* должны быть одинаковые
libraryDependencies +=
"com.typesafe.akka" %% "akka-stream" % "2.5.11"
в Scala
import akka.stream._
import akka.stream.scaladsl._
Источник данных - пример числа от 1 до 100
val source: Source[Int, NotUsed] = Source(1 to 100)
NotUsed тут это "материализованное значение", об этом позже
Вот так можно обработать значения:
val result: Future[Done] = source.runForeach(i ⇒ println(i))
для запуска потребуется implicit Materializer - интерпретатор потока
Materializer строит логику выполнения из композиции элементов и акторов.
implicit val system: ActorSystem = ActorSystem("QuickStart")
implicit val mat: Materializer = ActorMaterializer()
обычно создается один Materializer на приложение
Как может быть устроен Source? Рассмотрим на примере устаревшего ActorPublisher
(интерфейс слишком низкоуровневый и от него отказались в пользу более удобных инструментов)
class MyPublisher(source: Iterator[Int])
extends ActorPublisher[Int] {
override def receive = {
case Request(_) => sendNext()
case Cancel => context.stop(self)
}
private def sendNext() {
while (isActive && totalDemand > 0) {
if (source.hasNext)
onNext(source.next())
else
onCompleteThenStop()
}
}
}
Интеграция через Source.queue
val source: Source[Int, SourceQueueWithComplete[Int]] =
Source.queue[Int](bufferSize = 1000,
OverflowStrategy.backpressure)
// backpressure или выбрасываем элементы val queue: SourceQueueWithComplete[Int] = source
.to(Sink.foreach(println))
.run()
// очередь - "материализованное" значениеval result: Future[QueueOfferResult] = queue.offer(1000)
// при backpressure нужно ждать вычисления FutureОбычно источники это готовые реализации для:
- Выборок из баз данных
- Чтения из сокетов, HTTP, т.п.
- Чтения из файлов
- "Тиков" часов (таймера)
Sink - конечная точка, например
- Sink.seq - сборка коллекции
- Sink.fold - аналог foldLeft для коллекций
- Sink.head/last - первый/последний элемент
- FileIO.toPath - запись в файл
- Сеть, СУБД и т.п.
Пример: сумма элементов
val result: Future[Int] =
Source(Seq.range(1, 1000))
.runWith(Sink.fold(zero = 0)(_ + _))
Функция map/filter для потоков
Source(Range(1, 1000))
.map(_ + 1)
.filter(_ % 2 == 0)
.map(_ * 2)
.to(Sink.ignore) // игнорируем результат
По умолчанию runtime выполняет операции в одном потоке, собирая цепочки вызовов ("operator fusion").
Это оптимизация для цепочек из простых вызовов, таких много например в akka-http
Для распараллеливания стадий нужно расставить барьеры:
Source(Range(1, 1000)) // первый thread
.map(_ + 1).async // барьер оптимизации
.filter(_ % 2 == 0) // второй thread
.map(_ * 2)
.to(Sink.ignore)
при многопоточной работе применяются небольшие буферы между стадиями обработки
Применение асинхронной функции
def process(v: Int): Future[Int] = ???
Source(Range(1, 1000))
.mapAsync(parallelism = 16)(process) // сохраняет порядок
.mapAsyncUnordered(parallelism = 16)(process) // эффективнее
.to(Sink.ignore)
Пример: замена Future.sequence из 5-й части
def process(v: Int): Future[Int] = ???
val processed: Future[Seq[Int]] =
Future.sequence(Seq.range(1, 10000).map(process))
Проблемы:
- Много параллельных вызовов process не дожидаясь ответа - не все сервисы это любят.
- Забиваем executor мелкими задачами
Замена на потоках:
import immutable.Seq // Akka требует immutable
private val result: Future[Seq[Int]] = Source(Seq.range(1, 1000))
.mapAsync(parallelism = 16)(process)
.runWith(Sink.seq)
контроллируем число параллельных process
Flow - обработчик потока
source.map(_ + 1).to(Sink.ignore)
можно разобрать на части:
val flow: Flow[Int, Int, NotUsed] = Flow[Int].map(_ + 1)
source.via(flow).to(Sink.ignore)
Ограничение скорости обработки:
Source(Seq.range(1, 1000))
.throttle(50, 1.second, 1, ThrottleMode.shaping)
.mapAsync(16)(process)
.runWith(Sink.ignore)
50 элементов в секунду
Группировка:
def processBatch(v: Seq[Int]): Future[Seq[Int]] = ???
source
.groupedWithin(1000, 1 minute) // до 1000, в течении минуты
.mapAsync(16)(processBatch)
.mapConcat(identity) // поток Seq[Int] в поток Int
.runWith(Sink.ignore)
обработка "пачками" часто эффективнее
Несколько источников:
val source1 = Source(Seq.range(1, 1000))
val source2 = Source(Seq.range(1, 1000))
// один за другим
source1.concat(source2)
// по 10 из каждого по порядку
source1.interleave(source2, 10)
// в порядке готовности
source1.intersperse(source2)
GraphDSL: сложные схемы - расщепление, циклы
Пример: два обработчика потока
val tweets: Source[Tweet, NotUsed] = ???
val writeAuthors: Sink[Author, NotUsed] = ???
val writeHashtags: Sink[Hashtag, NotUsed] = ???
продолжение на следующем слайде
val g = RunnableGraph.fromGraph(GraphDSL.create() { implicit b =>
import GraphDSL.Implicits._
val bcast = b.add(Broadcast[Tweet](2))
tweets ~> bcast.in
bcast.out(0) ~> Flow[Tweet].map(_.author) ~> writeAuthors
bcast.out(1) ~> Flow[Tweet].mapConcat(_.hashtags.toList)
~> writeHashtags
ClosedShape
})
g.run()
Reactive Streams - стандартное API
Стандартное API для работы с асинхронными потоками
Разработано для интеграции разных реализаций асинхронных потоков.
Например веб-сервера и драйвера СУБД.
Вошло в Java 9.
Стандарт состоит из спецификации и test kit.
Предназначен для разработчиков библиотек.
Кроме Play Framework и Akka стандарт поддерживается:
Spring Framework, RxJava, Vert.x, Netty; существуют драйвера
для многих СУБД и хранилищ (например JDBC, Cassandra, Elasticsearch,
Mongo, Kafka и др).
Поточные ответы в Play Framework
Play поддерживает поточные ответы
Ok.sendEntity(entity)
Entity - поток, contentType и режим передачи.
Известного размера - обычно файлы.
// ByteString - неизменяемый массив байт + rope
val source: Source[ByteString, _] = response.bodyAsSource
HttpEntity.Streamed(source, Some(contentLength),
contentType = None)
размер полезен для индикации прогресса.
Chunked - длина неизвестна, отдача блоками:
HttpEntity.Chunked(source.map(HttpChunk.Chunk),
contentType = None)
последний блок нулевого размера
Неизвестного размера, отдача потоком
HttpEntity.Streamed(source, contentLength = None,
contentType = None)
для бесконечный потоков,
например Server Sent Events
Chunked vs Streamed?
- Chunked позволяет отличить конец передачи и разрыв соединения
- Chunked не требует разрыва соединения после передачи. Это важно, особенно для HTTPS.
- Streamed хорош для бесконечных потоков - меньше overhead, проще.
HTTP Клиент в Play может отдать Source
wsClient
.url(url)
.withQueryStringParameters(params: _*)
.stream() // Future[WSResponse]
// response.bodyAsSource: Source[ByteString, _]
Из этого легко собрать прокси:
- Собрать запрос, передать тело запроса если оно есть
- Вытащить размер из заголовков, определить режим передачи
- Перенести нужные заголовки, Content-Type
- Добавить обработку ошибок
Напоминаю:
- Страничка курса: https://maxcom.github.io/scala-course-2018/
- Посещения - отмечаем на листочке