Часть 3. Персистентные структуры данных. Ленивые вычисления. Монады.
Страничка курса: https://maxcom.github.io/scala-course-2018/
План
- Практическое задание: пишем классификатор
- Разбор домашних заданий
- Персистентные структуры: Vector и HashMap
- "call by value" и "call by name"; lazy
- Stream: ленивый список.
- Монады и for.
- Пример: Eval из библиотеки cats.
Орг. вопросы
- Выложил видео первых 2-х лекций
- Новый план занятий
- Akka - будет!
Практическое задание: пишем классификатор
Классификатор - алгоритм, относящий входные данные к одному из предопределенных классов.
Разработаем классификатор, определяющий является ли короткий текст позитивным, негативным или нейтральным.
На старте программы обучим классификатор на готовых текстах с оценками.
После на основе статистики будем оценивать произвольный текст.
Реализуем наивный байесовский классификатор
- Один из наиболее часто используемых
- Прост в реализации и отладке
- Я нашел хорошее описание с примером на Scala
Денис Баженов: Наивный байесовский классификатор
В статье есть:
- Описание в применении к текстам
- Описание как запрограммировать
- Пример расчета - подойдет для тестов
- Пример реализации на Scala
Для обучения классификатора используем готовый корпус:
Корпус коротких текстов для настройки классификатора
При использовании корпуса, просьба ссылаться на следующую работу: Автоматическое построение и анализ корпуса коротких текстов (постов микроблогов) для задачи разработки и тренировки тонового классификатора
Что делаем:
- Классификатор с тестами
- Разбиение текста на слова с зачисткой
- Чтение корпуса твитов из CSV
- Программу, классифицирующую введенный текст
На реализацию есть две недели:
8-го марта занятий не будет.
Работу над кодом ведем на gitlab.com!
приватный github.com - тоже можно, у кого есть
Разбор домашних заданий
1. Судоку - много кода.
Нужно было поискать короткое красивое решение.
Вместо этого - много решений методом "грубой силы".
Старайтесь писать простой код - его проще отлаживать,
поддерживать и развивать.
2. Использование return
В Scala почти всё является выражением, 3. Доступ к спискам по индексу без необходимости
4. Комментарии вместо объявления функций
Задача программиста - разбить сложную задачу
на набор простых.
Коментарий - не средство декомпозиции
Такой код
Заводим функции, в Scala их можно создавать в любом блоке
5. Использование == в тестах
== оператор сравнения языка Scala, его нельзя переопределить
=== оператор из тестовой библиотеки
=== лучше, он:
6. Опасное использование "for"
раскажу позже сегодня
Зачем мы говорили о List? "Я видел такое, во что вы, люди, просто не поверите.
Штурмовые корабли в огне на подступах к Ориону. Я смотрел, как Си-лучи мерцают
во тьме близ врат Тангейзера.
Рой Батти не умеет работать с List :-(
Напомним проблемы List:
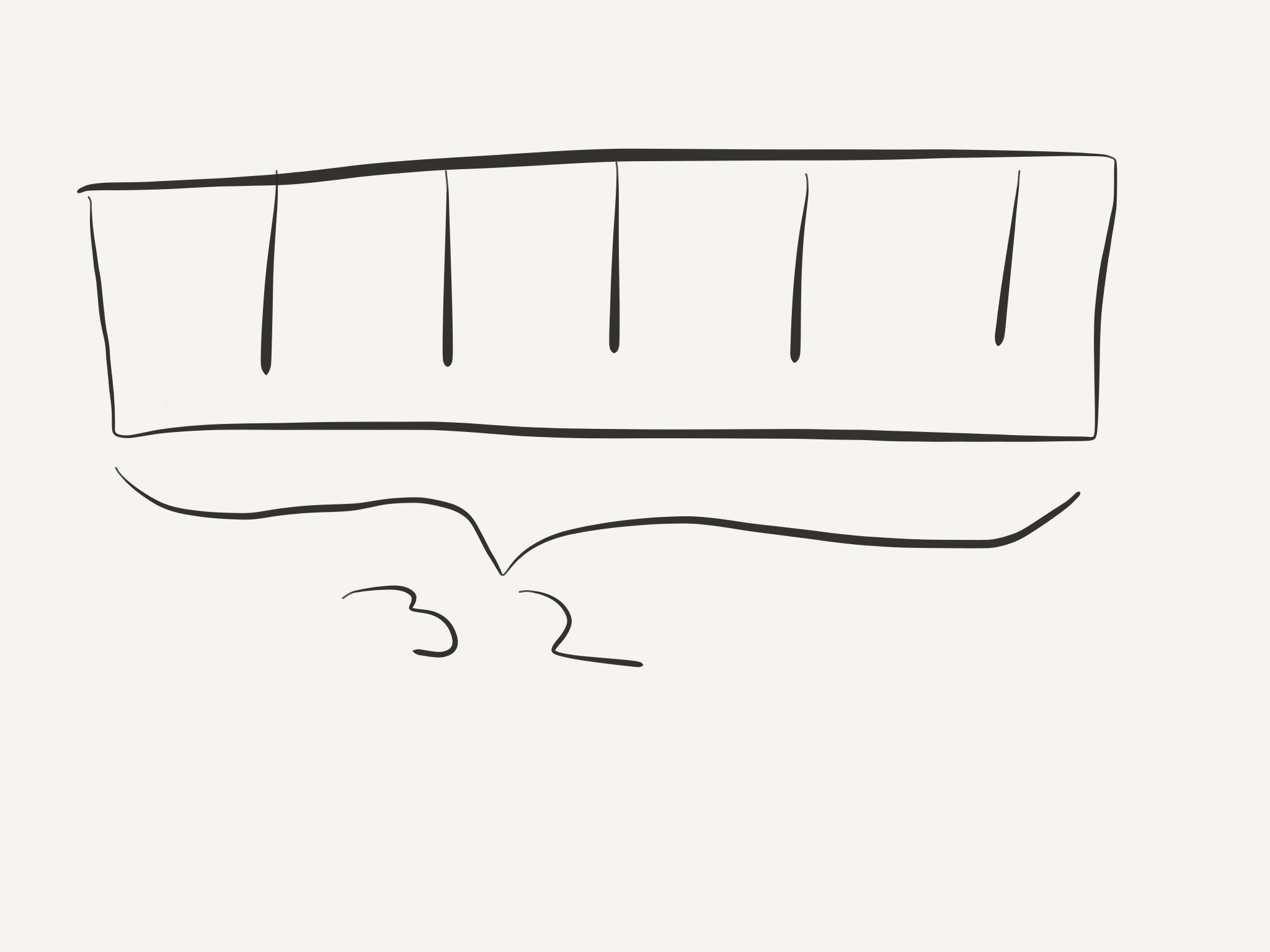
Vector - современная персистентная коллекция, без этих недостатков.
Используется и в Scala, и в Clojure
До 32 элементов
До 1024 элементов (32*32)
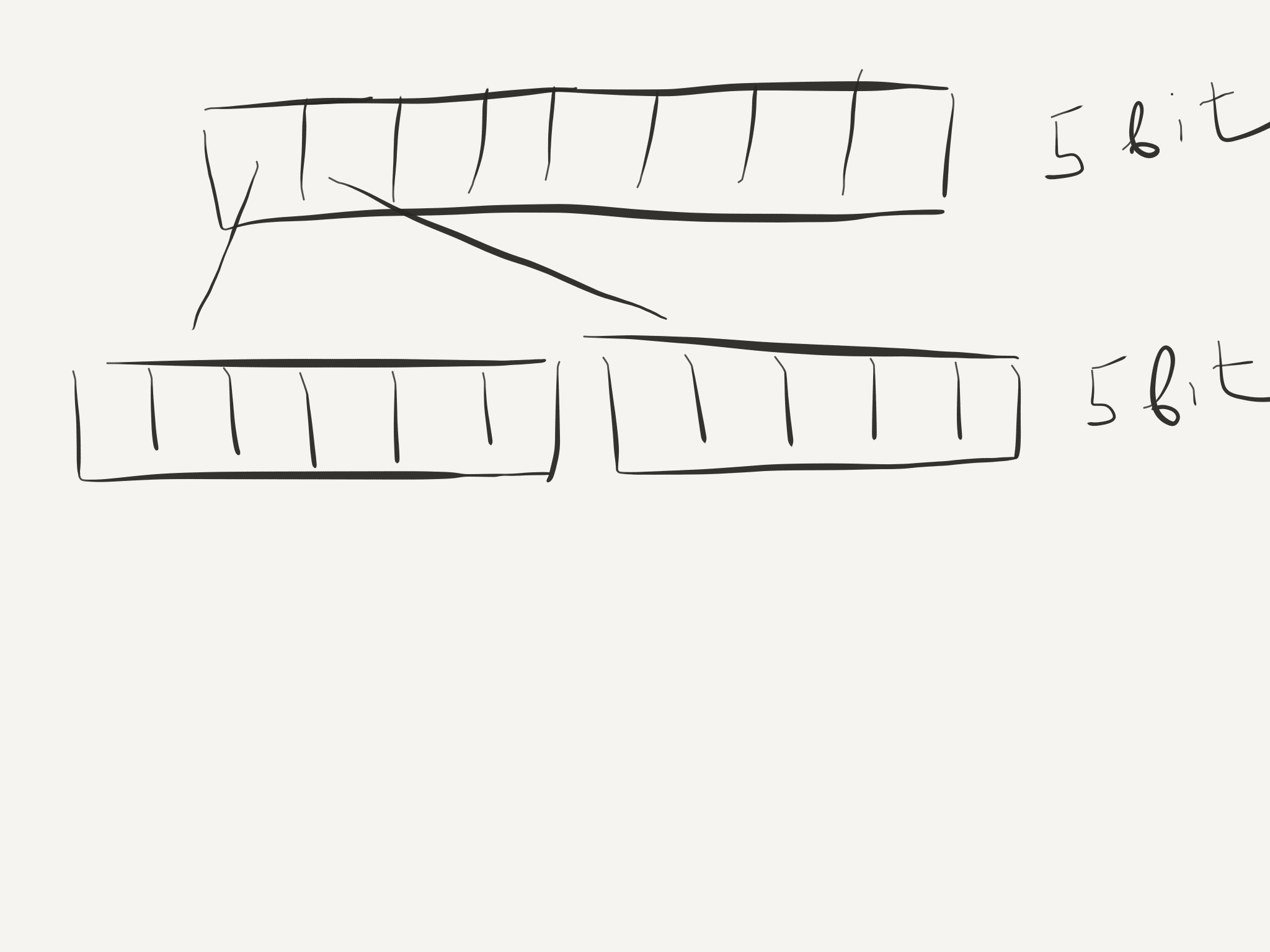
Очередной уровень
Добавление элемента - два уровня
Добавление элемента - три уровня
Добавление в начало - аналогично; Стоимость операций - effectively constant:
Почему effectively constant?
Максимум 6 уровней, это достаточно
Vector - не List:
для пользователя:
map/flatMap/filter/fold - аналогично В Scala эти операции не меняют тип исходной коллекции
Ключ - неизменяемый объект любого типа
Метод hashCode возвращает Int для любого объекта
Реализация - префиксное дерево с основанием 32
Похоже на вектор, только индексом выступает hashCode
Структура создается по мере необходимости, на каждом уровне могут быть
и данные, и ссылки на подуровни.
(картинка с слайда про Vector)
Добавление и удаление - effectively constant, Поиск - effectively constant, если хеш-функция хорошая. Откладываем вычисления до момента Параметры функции могут:
Пример: Option.getOrElse
Значение вычисляется заново каждый раз
Создает новый список с разными элементами
такие вызовы похожи на передачу функции без аргументов
"Ленивые" значения - вычисляются один раз,
результат сохраняется (memoization)
В worksheet не работает - "эффект наблюдателя"
lazy работает и в классах, и внутри функций
Превращаем call by name в lazy:
Еще пример - регистронезависимый id
демо-код, с некоторыми языками будут проблемы
Структура похожа на List
Два вида ячеек:
Cons ячека вычисляет "хвост" при обращении, Функции тоже работают лениво, например map:
Пример реализации map:
Функции, обходящие весь список "форсируют" его. Stream может быть бесконечным
Фибоначчи: каждое последующее число равно сумме двух предыдущих чисел
Применение:
Основное практическое применение:
Минусы:
«Монада — всего лишь моноид из категории эндофункторов, что может быть проще?»
(c) A Brief, Incomplete, and Mostly Wrong History of Programming Languages
Для нас монада - шаблон проектирования.
Много типов из разных областей являются монадами.
Монада - значение, помещенное в контекст.
Операции:
Рассмотрим на примере Option
Последовательное вычисление пока не встретится None
for в Scala – не цикл
for { ... } yield { ... } Комбинирует flatMap и map for без yield использует forearch вместо последнего map
Посмотрите "desugar for" в IDEA
Еще про for - пример из домашнего задания
Компилятор это преобразует в
withFilter - это тот же фильтр, Данный код работает только потому, Причем ленивый именно так, как хотел автор кода.
Монада - абстракция цепочки связанных вычислений.
Монада контролирует выполнение этой цепочки.
Законы, которые должны выполнять монады
"Left Identity"
pure(x).flatMap(f) == f(x)
применение функции к значению в монаде
эквивалентно применению функции к значению
"Right Identity"
m.flatMap(pure) == m
применение функции создания не меняет монаду
ассоциативность
m.flatMap(f).flatMap(g) == уравнивает разные способы комбинации функций
Try - тоже монада; вычисляется пока не возникнет
исключение
Either - монада в Scala 2.12. Вычисляется правая сторона,
левая сторона - остановка вычисления.
Вычисления не обязательно должны происходить
прямо сейчас и в текущем потоке.
Future - монада, выполняющая
вычисление в другом потоке.
Операция flatMap позволяет избежать
цепочек callback'ов.
Рассмотрим её устройство на 5-й встрече.
Free - монада, свободная о какой-то реализации логики.
Собирает pipeline в структуру, которую
потом можно передать в интерпретатор.
Разделяет бизнес-логику и её реализацию.
Рассмотрим Eval из Cats - монаду, выполняющую
ленивые вычисления.
Напоминаю:
return не нужен.
var set: Set[Int] = Set()
for (i <- list.indices) {
set += list(i)
}
def checkSudoku(game: List[List[Int]]): Boolean = {
// rows
...
много кода с объявлениями переменных
...
//column
...
много кода с объявлениями переменных
...
// 3x3
...
много кода с объявлениями переменных
...
}
"rotate function" should {
"rotates left" in {
val l = List('a', 'b', 'c', 'd', 'e')
Rotator.rotate(2, l) == List('c', 'd', 'e', 'a', 'b')
}
}

Vector
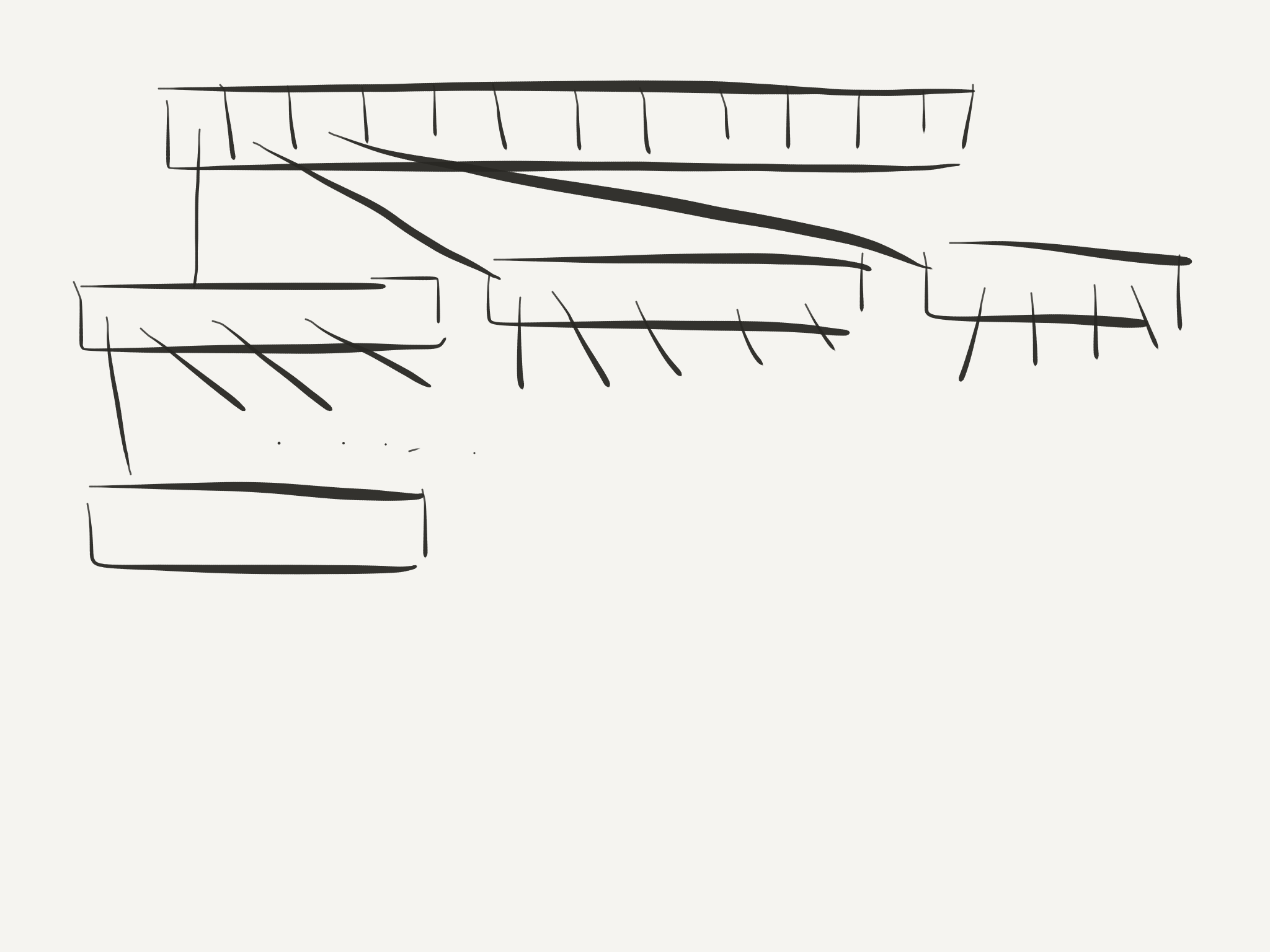
Vector хранит смещение первого элемента
HashMap
Map("one" > "first", "two" > "second", "three" -> "third")
m.get("one") // Some("first")
val m1 = m + ("five" -> "fifth") // добавление
val m2 = m - "one" // удаление
Seq[(K,V)]
m.map(p ⇒ p._1.toUpperCase -> p._2)
как у Vector.
Значения с одинаковым хеш-кодом хранятся в списке.
Ленивые вычисления
когда нужен результат
def getOrElse(opt: Option[Int], default: ⇒ Int): Int = {
opt match {
case None ⇒ default // вычисляется прямо тут
case Some(v) ⇒ v
}
}
// метод List[A]
def fill[A](n: Int)(elem: => A): List[A]
List.fill(10)(Random.nextInt)
lazy val
import java.time.{Duration, Instant}
lazy val lazyCurrent = Instant.now
val current = Instant.now
Thread.sleep(1000)
Duration.between(lazyCurrent, current)
// разница больше секунды
def repeat(n: Int, v : ⇒ Int) {
lazy val cached = v // вычисляется 0 или 1 раз
List.fill(n)(cached)
}
final case class UserId(id: String) {
private lazy val loId: String = id.toLowerCase()
override def equals(obj: Any) = {
obj match {
case other: UserId ⇒
other.loId == loId
case _ ⇒
false
}
}
override def hashCode() = loId.hashCode
}Stream: ленивый список
val s: Stream[Int] = 3 #:: 2 #:: 1 #:: Stream.empty
и сохраняет его. Только до следующего звена.
var n: Int = 0
val s: Stream[Int] = Stream.fill(100000) {
n += 1
Random.nextInt
}
s.map(_ * 2).take(1).toVector
println(n) // 1
def map(s: Stream[Int], f: Int ⇒ Int): Stream[Int] = {
if (s.isEmpty) {
s
} else {
f(s.head) #:: map(s.tail, f)
}
}
Например length или fold.
import scala.math.BigInt
lazy val fibs: Stream[BigInt] = BigInt(0) #::
BigInt(1) #::
fibs.zip(fibs.tail).map { n =>
n._1 + n._2
}
fibs.take(5).toVector
def findUserId(name: String): Option[Int] = ???
def loadUserById(id: Int): Option[User] = ???
val opt = Option("username") // создание
opt.flatMap(findUserId).flatMap(loadUserById)
(и еще filter и collect, но сейчас это не важно)
val jobTitle: Option[String] = for {
name <- opt // первая операция определяет тип
id <- findUserId(name)
user <- loadUserById(id)
} yield {
user.jobTitle
}
opt.flatMap(name =>
findUserId(name).flatMap(id =>
loadUserById(id).map(user =>
user.jobTitle)))
opt match {
case Some(name) ⇒
findUserId(name) match {
case Some(id) ⇒
loadUserById(id) match {
case Some(user) ⇒ user.jobTitle
case None ⇒ None
}
case None ⇒
None
}
case None ⇒
None
}
def forall(list: List[Int], f: Int ⇒ Boolean): Boolean = {
var result = true
for (elem <- list if result)
result = f(elem)
result
}
def forall(list: List[Int], f: Int ⇒ Boolean): Boolean = {
var result = true
list.withFilter(_ => result).foreach(elem => result = f(elem))
result
}
только оптимизированный для for
что withFilter - ленивый.
m.flatMap(x => f(x).flatMap(g))
import cats.Eval
case class User(id: Int, info: String)
def loadUserById(id: Int): User = ???
// строим pipeline
val result = for {
v <- Eval.now(10)
user <- Eval.later(loadUserById(v))
} yield {
user.info
}
// вычисление происходит тут
result.value